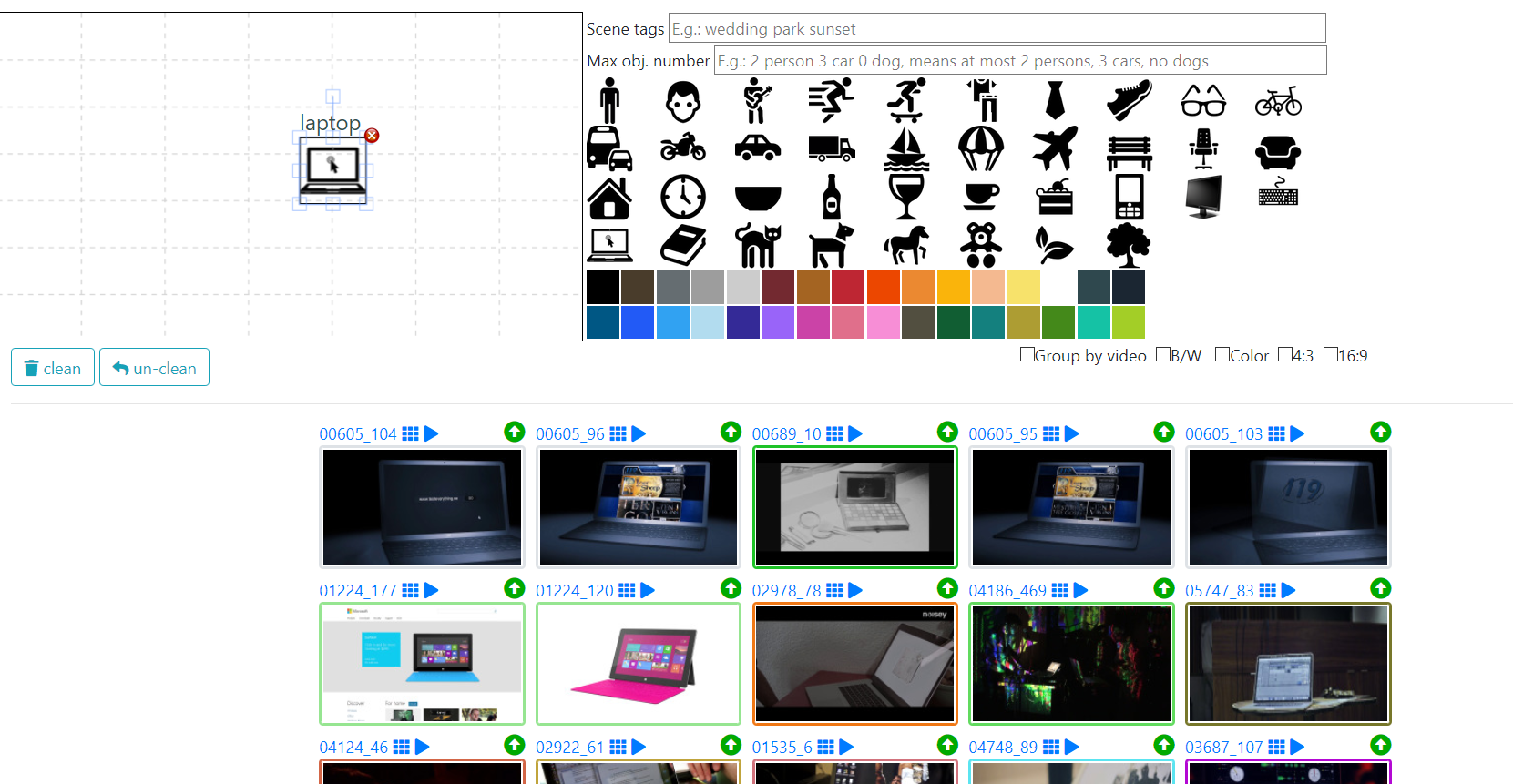
Video Browsing
We are working on a large-scale video retrieval system effective, fast, and easy to use for content search scenarios that are truly relevant in practice (e.g., known-item search in an ever-increasing video archive, as nowadays ubiquitous in many domains of our digital world). VISIONE is a content-based video retrieval system that participated to VBS for the very first time in 2019. It is mainly based on state-of-the-art deep learning approaches for visual content analysis and exploits highly efficient indexing techniques to ensure scalability. The system supports query by scene tag, query by object location, query by color sketch, and visual similarity search.

Automatic Visual Detection of Face Masks Usage
Our approach to Personal Protection Equipment usage detection is now also able to detect usage of face masks according to COVID-19 prevention guidelines. Our solution is based on Deep Learning: the deep neural network is bootstrapped using large synthetic datasets automatically generated using virtual worlds and then fine-tuned on smaller manually labeled real datasets. More details here

Automatic Visual Social Distancing Measurements from Standard CCTV Cameras (Zero-Cost, Perspective-Aware)
Social distancing is a proven method that help us keep the spread of contagious diseases under control. During the COVID-19 pandemic, the World Health Organization established that a distance of about 1 meter among people is adequate to slow down the contagion. With this in mind, we developed a machine learning prototype that measures distances among persons by using a single image from a fixed camera. Assuming people moving on the same planar surface (e.g., roads), by using computer vision algorithms, it is sufficient to calibrate the camera with a simple method, so that the exact distance can be calculated anywhere in the captured frame, thus enabling all already-placed cameras be social distance controllers at near-zero cost.
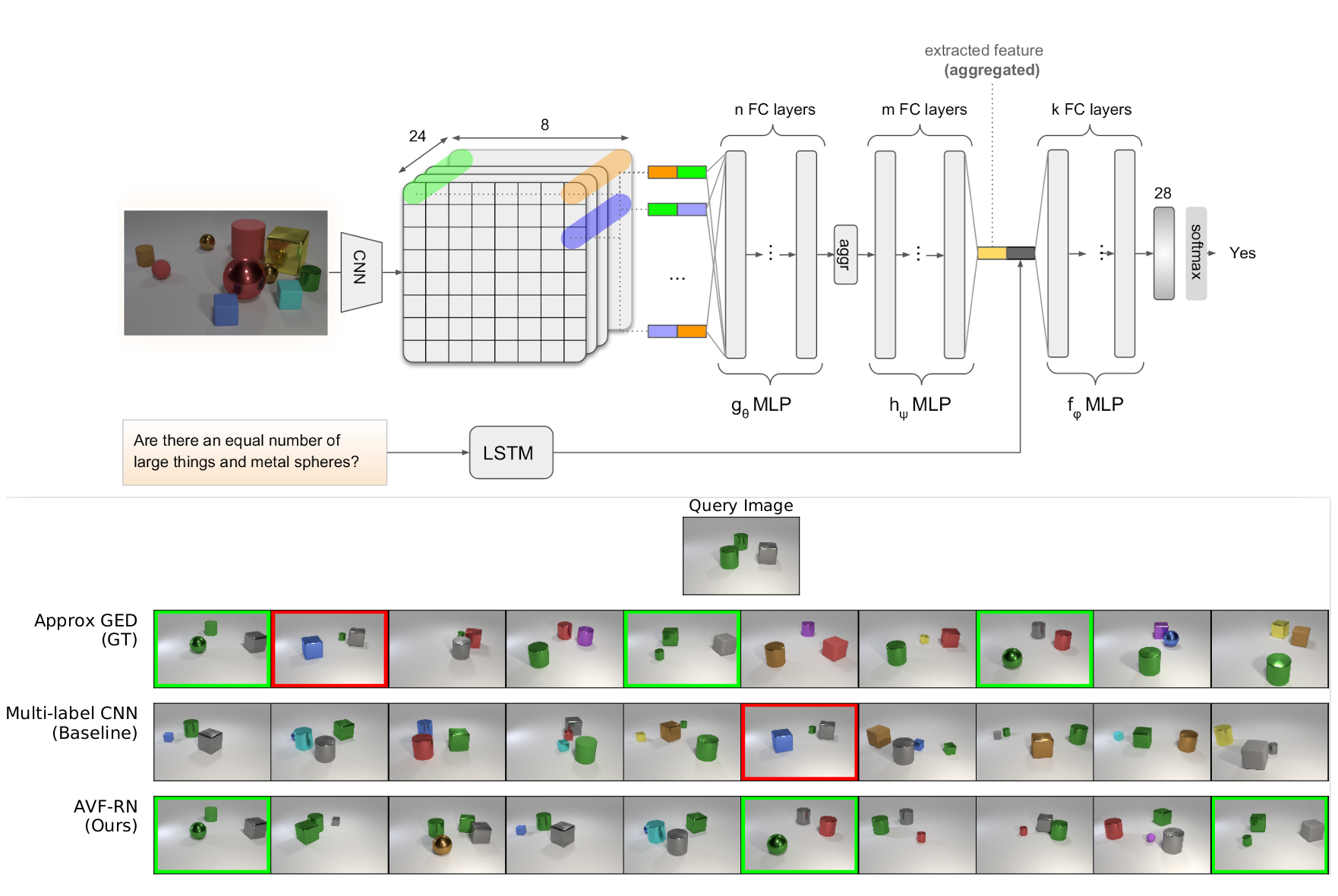
AI for Relational Reasoning
Relational reasoning refers to a particular kind of reasoning process that can understand and process relations among multiple entities. An entity is a generic term that materializes into different things: visual objects in an image, words in a sentence or chorus/riffs in songs. This research is aimed at discovering abstract relationships between entities both in the same modality (i.e.: the spatial arrangement of objects in an image) and among different modalities (i.e.: grounding a sentence onto the image it describes). Relational reasoning research spans different AI interesting areas and can be applied to different tasks, such as Visual Question Answering, Visual Relationships Detection, Abstract Reasoning, and Relational Image Retrieval.

Bio-inspired Deep Learning
The typical algorithms used to train Artificial Neural Networks are based on Gradient Descent with error backpropagation. In spite of the recent success of this approach, backpropagation of errors is considered to be implausible from a biological point of view. On the other hand, a biologically plausible learning scheme is based on the Hebbian principle: “Neurons that fire together wire together”. Starting from this simple principle, complex mathematical models of learning can be constructed. In particular, we explore the possibility of applying such models for training deep neural networks in order to solve AI tasks. A particular model that mimics the behavior of biological neurons more closely is that of Spiking Neural Networks (SNNs), considered as the third generation neural networks. In this model, neurons communicate by means of trains of pulses (spikes) and values are encoded in the frequency of spikes, not in their amplitude. The advantage of this communication paradigm is that it allows to implement complex neural functions with minimal power consumption, as it happens in the brain. This makes SNNs particularly well suited for hardware implementations, with potential applications on energy-constrained embedded devices.

Parking Lot Occupancy Visual Recognition
We developed solutions for Parking lot Occupancy Visual recognition which uses surveillance cameras to automatically decide about the occupancy of individual parking slots in a parking lot. We used techniques based on Deep Learning, and more specifically Convolutional Neural Networks, appositively designed to run on low computational power devices, as for instance smart cameras, or Raspberry devices. We also built two publicly available datasets (CNRPark and CNRPark+EXT) that can be used by researchers, willing to develop new solutions for Parking Lot Occupancy Visual Recognition, to perform objective comparisons with state of the art techniques. More details here.

AI for Visual Counting
The counting problem is the estimation of the number of objects instances in still images or video frames. This task has recently become a hot research topic due to its inter-disciplinary and widespread applicability and to its paramount importance for many real-world applications, for instance, counting bacterial cells from microscopic images, estimate the number of people present at an event, counting animals in ecological surveys with the intention of monitoring the population of a certain region, counting the number of trees in an aerial image of a forest, evaluate the number of vehicles in a highway or in a car park, monitoring crowds in surveillance systems, and others.
We have proposed some solutions able to count vehicles located in parking lots. In particular, we introduced a detection-based approach able to localize and count vehicles from images taken by a smart camera, and another one from images captured by a drone.

Face Recognition
We implemented several solutions based on Deep Learning approach and Convolutional Neural Networks (CNNs) to address the face recognition problem in different application scenarios. For example, we studied the problem of intrusion detection in a monitored environment, and we designed a system to automatically detect unauthorized accesses to a restricted environment by exploiting face recognition on the images acquired by a Raspberry Pi camera placed in front of the entrance of the monitored room. To this purpose, we collected an indoor face dataset that we used to perform our experiments. More details about the dataset can be found here.
We also have compared the recognition accuracy in performing the face recognition task by using the distance of facial landmarks and some CNN-based approaches. Facial landmarks are very important in forensics because they can be used as objective proof in trials, however, the recognition accuracy of these approaches is much lower than the ones based on Deep Learning. Recently, with the MoDro project, we started to investigate the possibility to move the face recognition computation inside embedded devices such as a Raspberry Pi so that they autonomously can perform this task without the need to transmit the video stream to a remote server for the analysis. Finally, we consider the task of detecting adversarial faces, i.e., malicious faces given to machine learning systems in order to fool the recognition and the verification in particular.

5G-Enabled Objects and Persons recognition for Unmanned Aircraft
Public safety has become a relevant aspect, especially in large urban areas. The possibility to act promptly in case of dangers or alarms can be of fundamental importance in determining the favorable outcome of the interventions. For example, identifying and tracking an individual or a suspicious vehicle that moves in an urban context may require a significant deployment of forces, with costs that sometimes can make the interventions ineffective. To this end, we tested applications of 5G for public security in the city of Matera. The experiments involved aerial drones and exploited the 5G mobile network provided by the Bari Matera 5G project consortium led by TIM, Fastweb (two Italian mobile telecommunication operators) and Huawei. Through these experiments, we were able to show that the 5G wireless communication technology can be successfully integrated with the drone technology, in order to create a synergy for the development of innovative and low-cost public security applications. In particular, we considered a scenario related to security in densely populated areas in which we recognize objects and persons from a video in real-time. For this scenario, we used a DJI Matrice 600 drone owing to its high lifting capabilities. The 5G connectivity was obtained through a TIM 5G Gateway, permanently mounted on the drone.

Learning Object Recognition with Virtual Worlds
The availability of large labeled datasets is a key point for an effective train of deep learning algorithms. Due to the high human effort required to obtain them, we explored an alternative way to automatically gather labeled data via synthetic rendering of virtual worlds.We developed a real-time pedestrian detection system that has been trained using a virtual environment provided by realistic video-games (GTA V). We introduced ViPeD, a new synthetically generated set of images extracted from a realistic 3D video game where the labels can be automatically generated exploiting 2D pedestrian positions extracted from the graphics engine. We exploited this new synthetic dataset fine-tuning a state-of-the-art computationally efficient Convolutional Neural Network (CNN). Experimental evaluation, compared to the performance of other existing approaches trained on real-world images, shows encouraging results. Collecting data from virtual worlds enables also applications in which data often do not exist and is difficult to gather, e.g. car accidents, fights, and other hazardous scenarios. To this end, we explored the detection of personal protection equipment (like helmets, ear protection, and high visibility vests) in working places with safety requirements. As data for this scenario do not exist, we exploited the game engine and models to synthesize VW-PPE, a dataset of detection of personal protection equipment in virtual work environments. Using VW-PPE to pretrain deep-learning-based object detector, we were able to obtain better models when deployed on real-world scenarios.
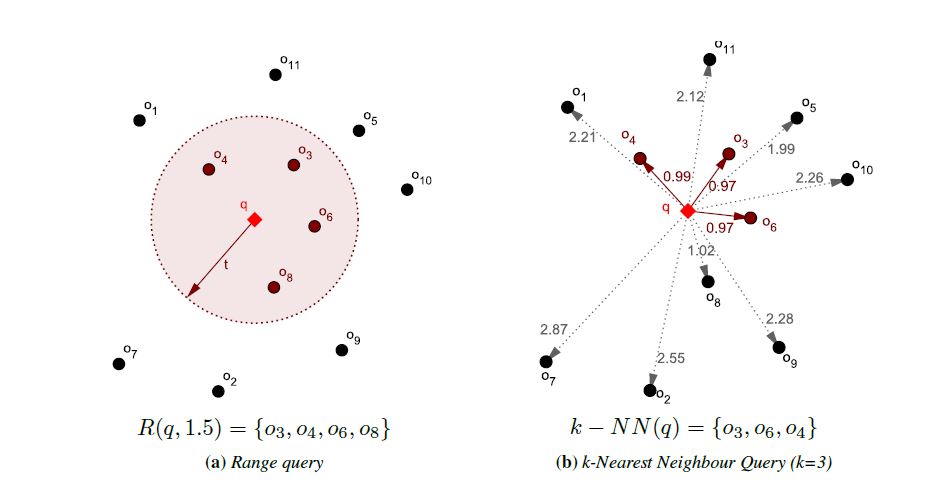
Similarity Search
Searching a data set for the most similar objects to a given query is a fundamental task in many branches of computer science, including pattern recognition, computational biology, and multimedia information retrieval, to name but a few. This search paradigm, referred to as similarity search, overcomes limitations of traditional exact-match search that is neither feasible nor meaningful for complex data (e.g., multimedia data, vectorial data, time-series, sensor data, etc.). In our research, we mainly focus on approximate search techniques, as it has been proven that exact search methods scale poorly with the dimensionality of the data (the curse of dimensionality) and the size of the data set. One way to speed-up the metric searching is to transform the original space into a more tractable space where the transformed data objects can be efficiently indexed and searched. We developed and proposed various techniques to support approximate similarity research in metric spaces, including approaches that rely on the transformation of data objects into permutations (permutation-based indexing), low-dimensional Euclidean vectors (nSimplex projection), or compact binary codes (sketching technique). Moreover, we identified a large class of metric spaces, called supermetric spaces, for which we have derived a series of techniques that improve the performance of indexing and searching these spaces.