
AIMIRFace
AIMIRFace is a face dataset of 39,037 faces belonging to 42 different persons collected from two different cameras in two offices of CNR-ISTI in Pisa over a period of 18 months.

NDISPark – Night and Day Instance Segmented Park
NDISPark is a small manually annotated dataset of cars in parking lots, describing most of the problematic situations that we can find in a real scenario. It is suitable for the counting task and for instance segmentation. It is worth noting that images are taken during the day and the night, showing utterly different lighting conditions.

GTA – Grand Traffic Auto
Grand Traffic Auto is a vast collection of about 10,000 synthetic images of urban traffic scenes collected using the highly photo-realistic graphical engine of the GTA V – Grand Theft Auto V video game. To generate this dataset, we designed a framework that automatically and precisely annotates the vehicles present in the scene with per-pixel annotations.

ViPeD
ViPeD is a synthetically generated set of pedestrian scenarios extracted from a realistic 3D video game where the labels are automatically generated exploiting 2D pedestrian positions. It extends the JTA (Joint Track Auto) dataset, adding real-world camera lens effects and precise bounding box annotations useful for pedestrian detection.
YFCC100M-HNfc6
YFCC100M-HNfc6 dataset is a deep features extracted from the Yahoo Flickr Creative Commons 100M (YFCC100M) dataset created in 2014 as part of the Yahoo Webscope program. The dataset consists of approximately 99.2 million photos and 0.8 million videos, all uploaded to Flickr between 2004 and 2014 and published under a Creative Commons commercial or non commercial license.
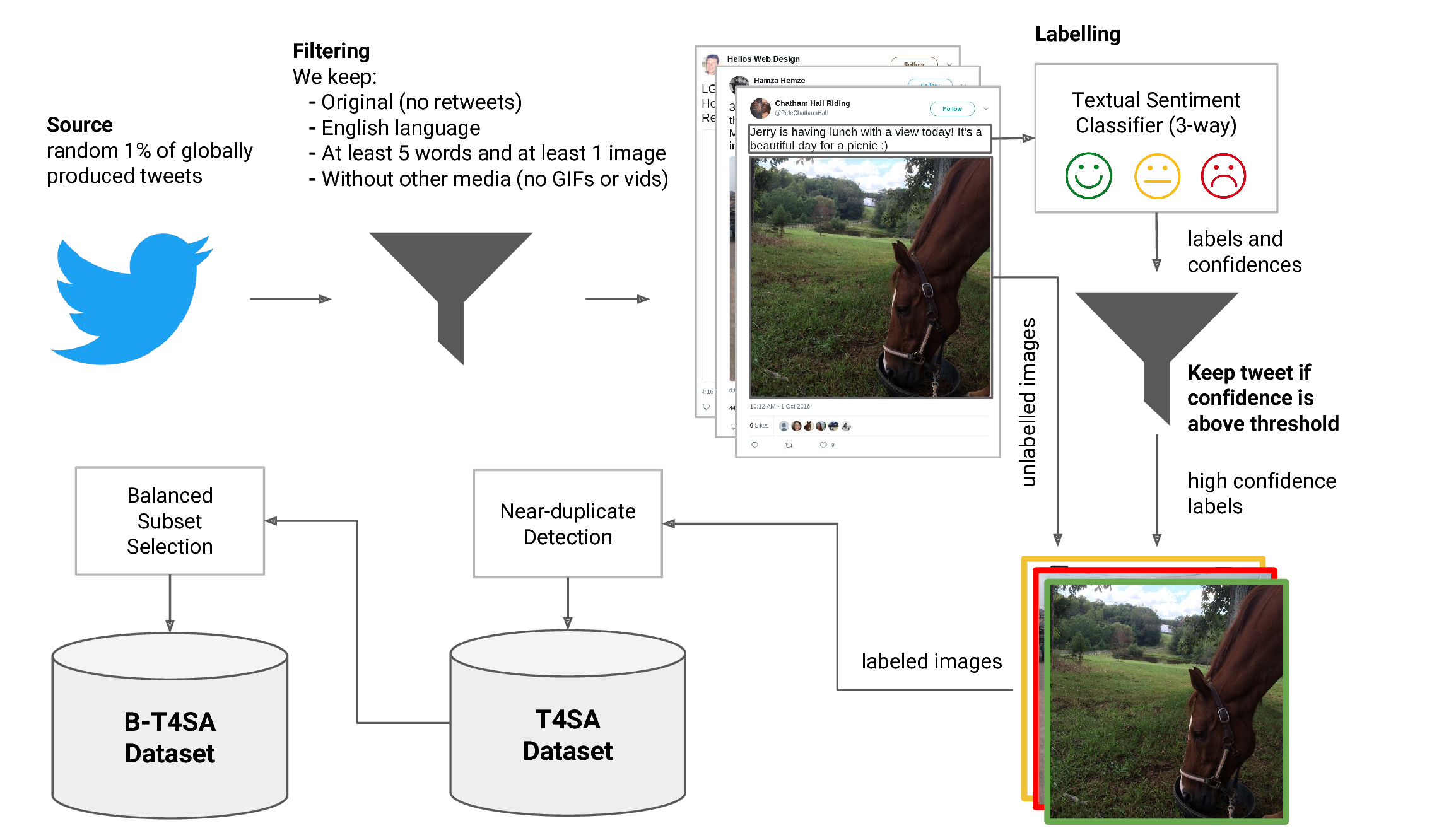
t4sa
3 million tweets (text and associated images) labeled according to the sentiment polarity of the text (positive, neutral and negative sentiment) predicted by a tandem LSTM-SVM architecture, obtaining a labeled set of tweets and images divided into 3 categories we called T4SA. We removed near-duplicate images and we selected a balanced subset of images, named B-T4SA, that we used to train our visual classifiers.

CNRPark
CNRPark is a benchmark of about 12,000 images of 250 parking spaces collected in different days, from 2 distinct cameras, which were placed to have different perspectives and angles of view, various light conditions and several occlusion patterns. We built a mask for each parking space in order to segment the original screenshots in several patches, one for each parking space. Each of these patches is a square of size proportional to the distance from the camera, the nearest are bigger then the farthest. We then labelled all the patches according to the occupancy status of the corresponding parking space.
CNRPark +EXT
CNRPark-Ext is a dataset of roughly 150,000 labeled images of vacant and occupied parking spaces, built on a parking lot of 164 parking spaces. CNRPark-EXT includes and significantly extends CNRPark.

CoPhIR
A collection of 100 million images, with the corresponding descriptive features, to be used in experimenting new scalable techniques for similarity searching, and comparing their results. In the context of the SAPIR (Search on Audio-visual content using Peer-to-peer Information Retrieval) European project, we had to experiment our distributed similarity searching technology on a realistic data set. Therefore, since no large-scale collection was available for research purposes, we had to tackle the non-trivial process of image crawling and descriptive feature extraction (we used five MPEG-7 features) using the European EGEE computer GRID.

VW-PPE
A dataset for training and testing techniques for Personal Protection Equipment recognition. It includes both images coming from virtual worlds and real world.

MOBDrone
The MOBDrone is a large-scale dataset of aerial footage of people who, being in the water, simulated the need to be rescued. It contains 66 video clips with 126,170 frames manually annotated with more than 180K bounding boxes (of which more than 113K belong to the “person” category). The videos were gathered from one UAV flying at an altitude of 10 to 60 meters above the mean sea level.
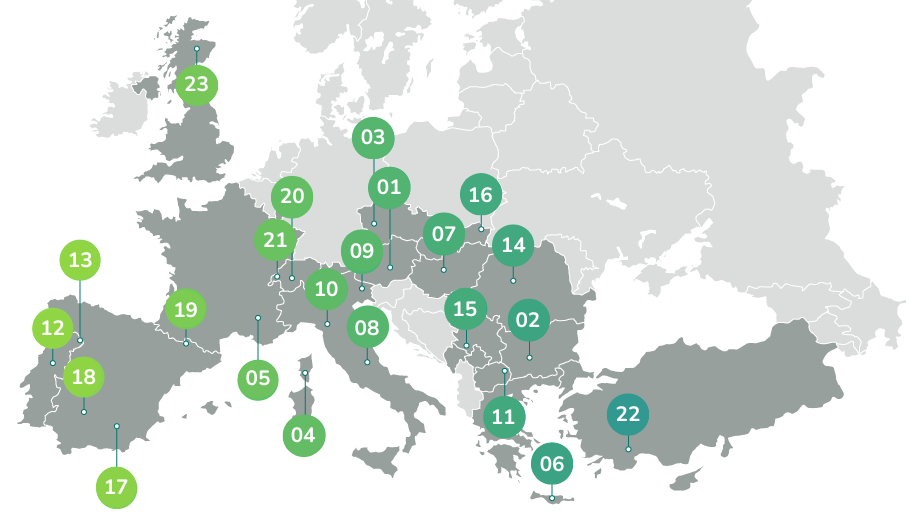
A Knowledge Graph of European Mountain Value Chains
This collection contains materials and data about 454 value chains from 23 rural European areas of 16 countries, obtained through a semi-automatic workflow that transforms raw textual data from an unstructured MS Excel sheet into semantic knowledge graphs. The MS Excel sheet contains details about all the value chains and is provided by the MOuntain Valorisation through INterconnectedness and Green growth (MOVING) European project.
Detailed information about the dataset is provided in the paper by Bartalesi, V., Coro, G., Lenzi, E. et al. “A Semantic Knowledge Graph of European Mountain Value Chains.” Scientific Data, 11, 978 (2024). https://doi.org/10.1038/s41597-024-03760-9